
最近想对博客做一下SEO优化,但是里面还是遇到了一些坑的,写来记录一下。
Hexo做SEO优化
对Hexo做SEO优化主要做了以下几个部分:
首页title优化
更改index.swig文件(your-hexo-site\themes\next\layout\index.swig),将
1 | {% block title %} {{ config.title }} {% endblock %} |
改为
1 | {% block title %} {{ config.title }} - {{ theme.description }} {% endblock %} |
这样更符合网站名称 - 网站描述这种格式。
生成sitemap并提交百度
- 1.安装sitemap自动生成插件
1 | npm install hexo-generator-sitemap --save |
- 2.在
主题配置文件中添加配置
1 | sitemap: |
- 3.在
站点配置文件中修改URL
1 | url: http://www.admintony.com |
添加nofollow标签
nofollow标签是由谷歌领头创新的一个“反垃圾链接”的标签,并被百度、yahoo等各大搜索引擎广泛支持,引用nofollow标签的目的是:用于指示搜索引擎不要追踪(即抓取)网页上的带有nofollow属性的任何出站链接,以减少垃圾链接的分散网站权重。
以hexo的NexT主题为例,需要修改两处:
- 1.找到footer.swig,路径在
your-hexo-site\themes\next\layout\_partials
将下面代码
1 | {{ __('footer.powered', '<a class="theme-link" href="http://hexo.io">Hexo</a>') }} |
改成
1 | {{ __('footer.powered', '<a class="theme-link" href="http://hexo.io" rel="external nofollow">Hexo</a>') }} |
将下面代码
1 | <a class="theme-link" href="https://github.com/iissnan/hexo-theme-next"> |
改成
1 | <a class="theme-link" href="https://github.com/iissnan/hexo-theme-next" rel="external nofollow"> |
- 2.修改sidebar.swig文件,路径在
your-hexo-site\themes\next\layout_macro
将下面代码
1 | <a href="{{ link }}" target="_blank">{{ name }}</a> |
改成
1 | <a href="{{ link }}" target="_blank" rel="external nofollow">{{ name }}</a> |
将下面代码
1 | <a href="http://creativecommons.org/licenses/{{ theme.creative_commons }}/4.0" class="cc-opacity" target="_blank"> |
改成
1 | <a href="http://creativecommons.org/licenses/{{ theme.creative_commons }}/4.0" class="cc-opacity" target="_blank" rel="external nofollow"> |
可以使用chinaz站长工具进行各项检测。
添加robots.txt
- 1.添加蜘蛛协议(放在
blog\source目录下)
1 | # hexo robots.txt |
- 2.在百度站长平台监测并更新Robots
修改文章链接
HEXO默认的文章链接形式为domain/year/month/day/postname,默认就是一个四级url,并且可能造成url过长,对搜索引擎是十分不友好的,我们可以改成 domain/postname的形式。编辑站点_config.yml文件,修改其中的permalink字段改为permalink: :title.html即可。
keywords和description
在\scaffolds\post.md中添加如下代码,用于生成的文章中添加关键字和描述。
1 | keywords: |
在\themes\next\layout\_partials\head.swig有如下代码,用于生成文章的keywords。
1 | {% if page.keywords %} |
文章的摘要会变为description。
主动推送插件
- 1.安装
hexo-baidu-url-submit插件
1 | npm install hexo-baidu-url-submit --save |
- 2.配置站点的
_config.yml文件
1 | baidu_url_submit: |
- 3.加入新的deployer(站点的
_config.yml文件)
1 | deploy: |
从github迁至coding
github是禁止百度蜘蛛爬行的,所以无法收录,因此将博客从Github迁移到了coding上,coding没有屏蔽百度蜘蛛,很方便被收录。
遇到的问题
主要遇到了以下几点问题:
- 1.
admintony.com和wwww.admintony.com收录情况不同
不加www的属于顶级域名;加www的属于顶级域名的子域名,对搜索引擎来说这两种域名是不同的站点。从而自然收录也会不一样。查收录时加www查到的数据是带www的这个制定网址网站的收录量;不加www的则还包括所有的二级域名网页收录在内。所以一般情况下,不加www比加www的收录量要大。
- 2.URL规则已经改成
http://域名/文章名.html,但收录URL却是http://域名/年份/月份/天/文章名/
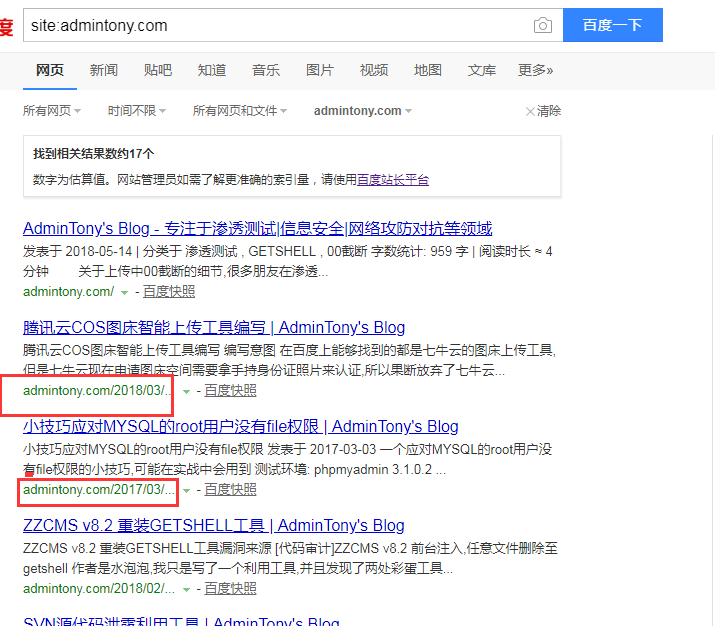
咨询了李春以后,得知,百度先将url对应的内容爬取到百度的数据库,然后再从数据库中去看内容是否符合百度的展示要求,因此爬去URL的内容和收录是有时间间隔的,所以我更换了URL规则,却收录的还是旧的URL规则。并且李春提示我要在百度进行网站改版。
网站改版
规则改版
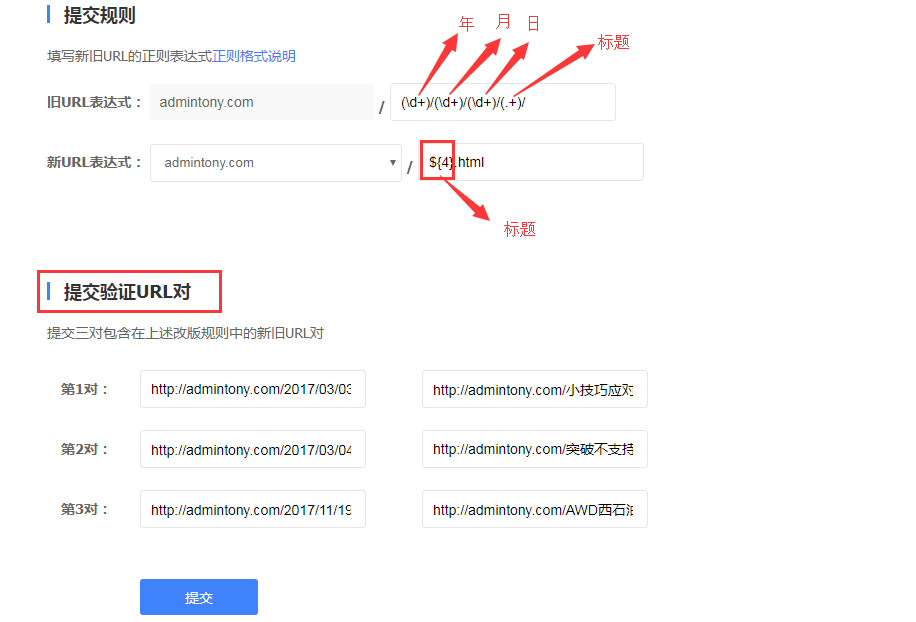
新旧链接301
要在旧链接中添加301跳转到新链接,301状态码表示永久性的迁移到新链接,用html实现代码如下:
1 | <META HTTP-EQUIV=REFRESH CONTENT="5;URL=http://www.admintony.com/SVN源代码泄露利用工具.html"> |
也就意味着,把17个链接都做一下301则需要在source目录下,创建年份/月份/日期/标题/index.html,且index.html中的跳转链接必须是新的链接,一个一个写的话会累死,所以写了一个代码实现,代码如下:
1 | # coding = utf-8 |
补充
昨天把规则提交以后出现了一些状况,如下:
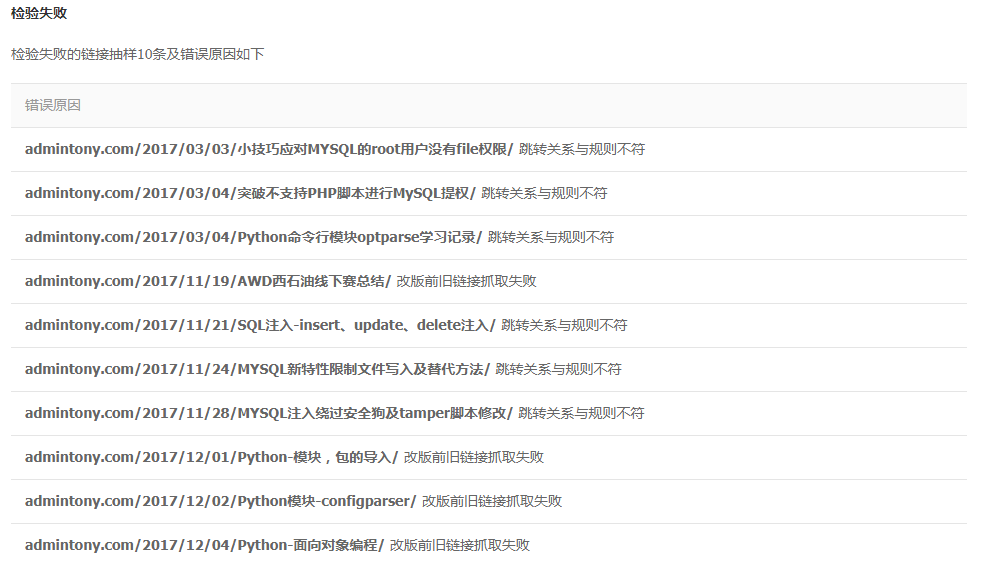
- 1.跳转关系与规则不符
对于这个错误我想了想具体是哪里出错了,后来想到在做301跳转的时候,把admintony.com的url都跳转到了www.admintony.com,而规则是填写的是admintony.com/${4}.html,所以出现这个错误。
解决方案:将301跳转到www.admintony.com改为跳转到admintony.com即可。
- 2.改版前旧链接抓取失败
做301跳转的时候,我只把百度收录的页面做了,而那些已经提交到百度数据库的页面,我并没有做301跳转,因此出现此错误。
博客一共写了49篇文章了,需要对49篇文章的旧链接都做一个301跳转,主要难题在于收集旧链接,站点已经更换了新链接,因此执笔写下工具来进行收集旧链接。
工具原理:正则匹配站点中的文章名称和发布时间,然后构造http://admintony.com/年份/月份/日期/文章名/并保存在url.txt。(工具在最下方)

在blog/source目录下用新旧链接301中的工具生成301跳转页面。
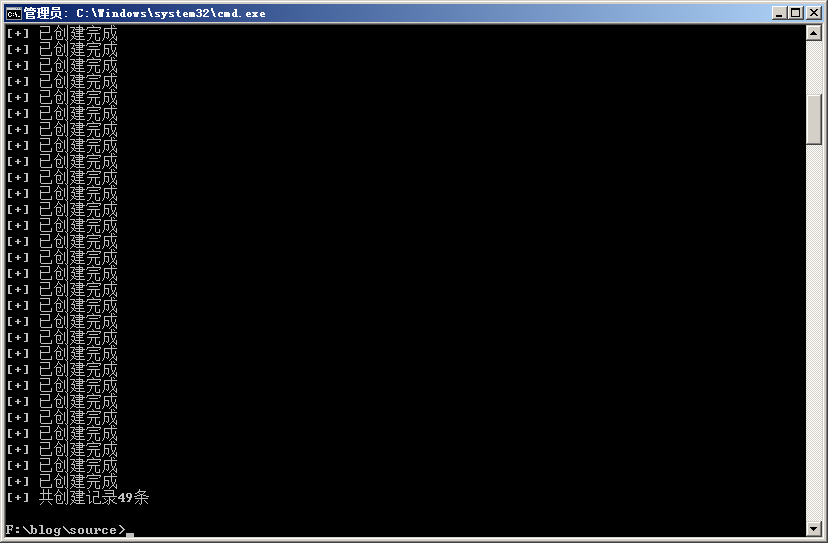
重新发布页面后,重新向百度申请网站规则改版即可。
1 | # coding = utf-8 |